


如何提高GPU使用效率——浅析GPU资源监控及虚拟化
【摘要】在数字化高度普及的时代,智能AI能力的应用已成为企业提升服务质量和效率的重要手段,GPU强大的计算能力可以加速自然语言处理模型的训练和推理过程,将GPU算力高效的应用到合适的场景中,可以为企业提供低成本且高质量的服务。但因现在客观存在GPU算力供应链卡脖子问题,GPU高端卡获取途径有限,中低端卡供应也出现供不应求,算力价格持续走高,算力资源尤为珍贵,在此背景下,GPU资源的高效利用显得尤为重要。如何高效利用GPU资源、提高资源利用率、降低系统的运营成本,从而以更低的成本为客户提供更好的服务,成为近年金融企业聚焦的一个热点。考虑提高GPU使用效率的方案,主要有加强资源监控,避免资源闲置以及做好资源使用、进行GPU池化和虚拟化。
【作者】哲哲蛙(笔名),某城商行技术经理,长期服务于信息技术部门,熟悉大型企业的IT数据中心基础平台的建设和维护工作。
一、GPU资源监控
1.1 GPU监控
为了提高GPU资源利用效率,必须得做好对资源使用效率的监控,避免应用程序对于GPU资源使用的“高配低效”。一些应用开发厂商或者维护人员,为了保证自己的程序运行,可能存在“圈地”思想,放大对于资源需求的评估,但实际运行并不需要那么大的资源,或者程序并非7*24小时都在相对高负荷运行,而是每天大多数时间段均空负载处于闲置状态。因此算力管理员就需要做好GPU资源监控,以便更好的掌握资源使用情况,及时评估和管理珍贵的GPU算力资源。
此外,GPU的监控对于提升应用能力,还能起到更多正向作用。通过GPU监控,确保模型训练和推理过程中GPU资源的稳定供应,加快模型的训练和更新速度,及时调整风险评估策略。通过监控GPU资源的使用情况,优化相关模型的训练和部署。
保障系统稳定性:银行的许多业务关键系统如风险评估、欺诈检测等依赖GPU的强大计算能力来处理大量复杂数据。通过实时监控GPU的温度、使用率、内存占用等指标,运维人员可及时发现潜在问题,避免系统崩溃或性能下降,确保银行业务的连续稳定运行。
优化资源分配:银行通常有多种业务同时运行,对GPU资源的需求各异。监控GPU的使用情况有助于了解不同业务在不同时段对GPU资源的占用,从而根据业务的优先级和资源需求动态分配GPU资源,提高资源利用率,降低运营成本。
提升业务效率:在人工智能和大数据分析广泛应用于银行业务的背景下,快速准确的GPU监控能够帮助银行更快地训练和部署机器学习模型,如信贷风险评估模型、市场趋势预测模型等,进而提升业务决策的速度和准确性,增强银行的市场竞争力。
1.2 GPU 监控的常用工具和技术
目前金融客户市场中主流的GPU仍然是英伟达,国内一些国产GPU也开始有了应用,国产GPU有图形渲染GPU和高性能计算GPU(GPGPU)两种。其中图形渲染GPU例如寒武纪MLU370、摩尔线程MTT S80;另一类高性能计算GPU,例如壁仞科技BR100、沐曦MXN AI和MXC GPGPU、中科曙光DCU以及近年生态稳步提升的华为昇腾显卡等。
目前针对GPU的监控,有硬件厂家自己提供的产品方案以及开源方案两种,例如NVIDIA官方提供的nvidia-smi工具,可用于查询和监控N卡GPU的状态信息,包括GPU的使用率、内存使用情况、温度、风扇转速等基本指标,硬件厂家提供的监控方案,通常有一定的局限性,只能提供针对自己的产品的监控能力。另外,一些开源方案例如GPUSTAT,则是基于Python 的轻量级命令行工具,利用nvidia-smi获取数据,并以命令行输出形式呈现GPU的状态和性能,支持自定义刷新率、选择要监视的GPU以及与其他监控系统集成,适用于自动化脚本和持续集成流程。目前国内一些平台监控GPU资源采用此方案较多,通过开源Prometheus 配置采集GPU的相关指标数据,配合Grafana进行图形化展示,将采集到的GPU数据以直观的图表形式展示,采用此方案的通常打造成一个通用的平台,提供多种GPU的监控能力。
以某城商行采用的监控方案为例,其企业探索采用的Prometheus结合Grafana监控方案,是在GPU Kubernetes集群中,通过部署kube-prometheus stack构建监控体系实现监控。其主要原理还是通过容器搭建管理平台,并通过容器的agent采集,向平台汇总数据如下:(a)每个运行vGPU组件的Kubernetes节点上部署DCGM-Exporter,定期从GPU设备中获取数据并通过HTTP接口暴露出来供Prometheus进行读取访问。创建ServiceMonitor资源对象,定义如何通过vGPU调度器收集指标。(b)部署了Prometheus定期抓取包括GPU算力、显存、温度等各种指标数据,将其存储在时间序列数据库中。(c)系统集成了Grafana可视化展示工具,配置Prometheus为数据源,并导入专为GPU监控设计的仪表板,提供了针对虚拟化GPU的关键性能指标,如算力利用率、显存使用情况等。通过可视化界面运维人员可以实时查看详细的GPU监控信息,从而及时发现潜在问题并优化资源配置策略,并且可以设置告警阈值,当GPU利用率过高、温度过高等情况发生时,自动发送告警通知,从而及时发现和处理潜在问题。
二、GPU资源的虚拟化技术
在GPU资源昂贵的背景下,采用GPU虚拟化技术,是提高资源利用率的一大利器。GPU 资源的虚拟化技术主要有基于硬件辅助的虚拟化、基于驱动隔离、基于 API 转发以及基于容器的GPU虚拟化几类。其中前两类主要是由硬件厂商提供的方案,而基于 API 转发以及基于容器的GPU虚拟化主要是用户态实现的虚拟化方案。
基于硬件辅助的虚拟化借助GPU硬件本身具备的虚拟化功能来实现资源的高效分配和共享。比如,一些GPU芯片内部设置专门的虚拟化模块,这些模块可以直接对GPU的核心、显存、缓存等重要资源进行精细的划分和管理,将一个GPU显卡物理上分割成多个小型显卡提供服务。以AMD 的部分GPU产品为例,其硬件辅助的虚拟化技术能够将GPU的计算单元、显存等按照预先设定的规则分配给不同的虚拟机或应用,实现硬件层面的资源隔离和共享。基于硬件辅助的虚拟化性能优势明显,由于是在硬件层面直接进行资源分配和管理,减少了软件层面的干预,能够最大程度地降低虚拟化带来的性能损失,提高GPU资源的利用效率,可以根据实际需求对GPU的各项资源进行配置,满足不同业务场景的要求。但这种方式最主要的短板在于对GPU硬件本身是否具备硬件划分能力要求较高,只有具备相应硬件虚拟化功能的GPU才能采用,且通常划分的颗粒度较粗。
基于驱动隔离的虚拟化,主要是通过对GPU驱动进行改造,使其能够在多个虚拟机或容器之间提供隔离的执行环境。GPU厂家通过自己的驱动虚拟化,给不同的 VM 或容器提供各自独立的驱动实例,这些实例共享物理GPU的硬件资源,不同的用户或应用在各自的虚拟环境中都能像独占GPU一样使用驱动功能。基于驱动隔离的虚拟化,提供了较好的隔离性,不同虚拟环境之间的干扰较小,能保障应用的稳定性和安全性。可以根据不同虚拟环境的需求灵活配置驱动参数,提高资源利用效率。对驱动的改造需要GPU厂商的支持,而且不同版本的驱动和GPU型号可能需要针对性的适配工作,开发和维护成本相对较高。
基于 API 转发的虚拟化,主要是通过在虚拟机(VM)和物理GPU之间拦截并转发图形应用编程接口(API)调用,实现多个 VM 对GPU的共享。例如,当 VM 中的应用程序发出 DirectX 或 OpenGL 等 API 调用时,中间层软件会截获调用命令,然后将其转发到物理GPU上执行,并把执行结果返回给 VM 中的应用。基于 API 转发的虚拟化实现相对简单,不需要对GPU硬件进行深度修改,能较好地支持多种现有的图形 API,兼容性较强,但由于涉及 API 调用的拦截和转发,可能会带来一定的性能开销,尤其在高负载场景下,对图形处理的实时性可能会有影响。
基于容器的GPU虚拟化是利用容器技术来实现对GPU资源的虚拟化管理,其本质其实是容器与API调用劫持相结合的方案。容器通过与宿主机的GPU驱动和相关管理工具配合,将GPU资源分配给各个容器使用。例如,在使用 Docker 容器管理GPU资源时,通过安装特定的 NVIDIA Docker 插件等方式,让容器能够访问和使用宿主机上的GPU资源。采用容器技术实现的虚拟化属于轻量级实现方案,启动速度快,相比虚拟机,容器在创建和运行过程中消耗的资源更少,能够更快速地部署应用并投入使用。资源共享灵活,容器可以根据自身的需求从宿主机的GPU资源池中灵活获取所需资源,实现了GPU资源在多个容器之间的动态分配。但是容器的隔离性相对虚拟机较弱,在某些对安全性和隔离性要求极高的应用场景中可能需要采取额外的措施来保障。如下图所示采用的是一种基于容器和CUDA劫持结合的实现方式,实现GPU core和memory隔离,通过细粒度地切分和隔离GPU核心与内存,它允许在同一物理GPU上运行多个容器,从而更有效地利用硬件资源,提高Kubernetes环境中GPU资源的利用率。其整体实现主要组件及工作原理如下:
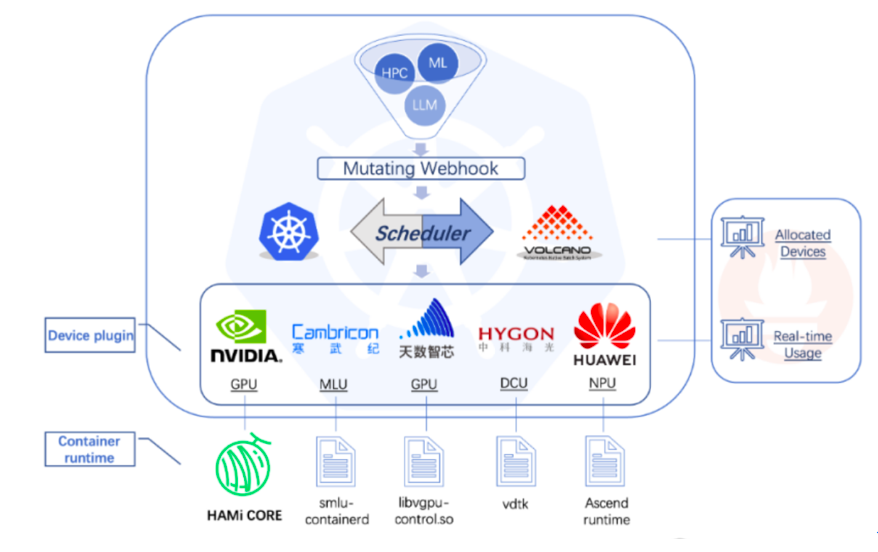
(1)Webhook:用于在Kubernetes中注册和验证自定义的资源请求,主要实现GPU虚拟化软件与Kubernetes API交互,并实现GPU资源的管理和调度。Webhook的工作原理是当用户创建一个请求vGPU资源的Pod时,kube-apiserver根据MutatingWebhookConfiguration配置调用Webhook。Webhook会检查Pod中的资源请求,如果发现是请求由GPU虚拟化软件管理的vGPU资源,则将Pod的SchedulerName字段改为vgpu-scheduler。此时该Pod就会由vgpu-scheduler进行调度。对于特权模式的Pod或指定了nodeName的Pod,Webhook会直接跳过或拒绝。
(2)Scheduler:GPU虚拟化软件包括自己的调度器(Scheduler),在创建Pod时做出决策,如何将GPU资源分配给不同的Pod。Scheduler (vgpu-scheduler)的工作流程是Vgpu-scheduler使用的是Kubernetes默认的kube-scheduler镜像,但通过配置KubeSchedulerConfiguration,它会调用一个名为Extender Scheduler的插件。该插件作为Vgpu-scheduler Pod中的另一个容器提供服务,实现自定义的调度逻辑,该调度逻辑具体来说包含三部分:(a)打分机制:根据每个节点上的已使用的GPU核心和内存资源与总资源的比例来计算得分,得分越高表示剩余资源越少。这有助于选择最合适的节点来放置Pod。(b)高级调度策略:包含 Spread、Binpack和Random三种调度策略,其中spread策略,倾向于将负载分散到不同的节点上以优化整体性能;而binpack策略则尽量集中负载,减少空闲资源,random则采用随机分配。(c)异步机制:包括GPU感知逻辑,通过定期上报Node上的GPU资源并写入Node的Annotations中,确保调度器能够获取最新的资源信息。
(3)GPU Device Plugin:GPU虚拟化软件通过自定义的GPU Device Plugin来实现对NVIDIA GPU的感知和资源分配,其主要功能包括:(a)GPU信息获取:使用NVML库获取节点上的GPU信息,包括型号、UUID、内存等,并根据配置对这些信息进行处理,如调整内存大小。(b)资源复制:为了符合Kubernetes的资源分配逻辑,会对物理GPU进行复制,生成多个虚拟设备供不同Pod使用,实现了GPU卡虚拟化复用能力。(c)环境变量设置:在分配GPU给Pod时,Device Plugin会设置一些环境变量,如CUDA_DEVICE_SM_LIMIT和CUDA_DEVICE_MEMORY_SHARED_CACHE,以及挂载必要的库文件,如libvgpu.so,以便替换容器中的原生驱动。
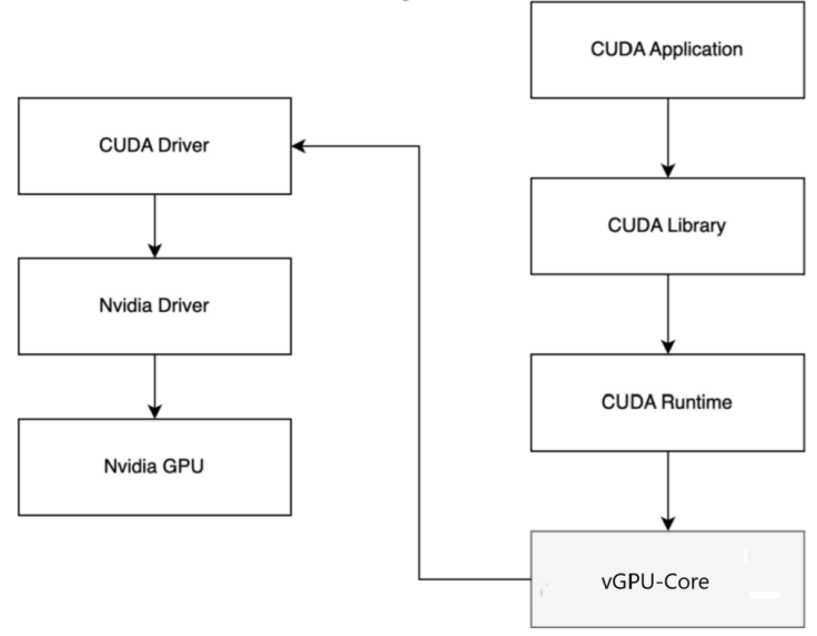
(4)vGPU-Core:GPU虚拟化软件通过拦截CUDA API来实现GPU资源的隔离和限制。这意味着它可以控制每个Pod使用的GPU资源,实现细粒度的GPU隔离。vGPU-Core是实现GPU资源隔离的关键部分,通过重写CUDA库(libvgpu.so)并替换容器中的相应库文件,实现对CUDA API的拦截。这样可以精确控制每个Pod访问的GPU核心数和内存大小,防止资源争抢。此外,vGPU-Core还处理了CUDA缓存共享等细节,确保多个Pod可以高效地共享同一块GPU。例如原生 libvgpu.so 在进行内存分配时,只有在 GPU 内存真的用完的时候才会提示 CUDA OOM,但是对于vGPU-Core实现的 libvgpu.so来说,检测到 Pod 中使用的内存超过了 Resource 中的申请量就直接返回 OOM,从而实现资源的一个限制。在执行 nvidia-smi 命令查看 GPU 信息时,也可返回 Pod Resource 中申请的资源,这样在查看时也进行隔离。
三、总结
总体而言,在GPU资源依然昂贵的今天,GPU资源的高效利用仍然是众多企业追求的目标,并且企业中国产GPU卡和N卡并存的局面仍然将长期存在,采用各硬件厂商提供的监控软件进行监控,可能带来更高的管理复杂度,此时建设一个整合有多路线的GPU监控能力的平台进行监控,通过监控数据合理规划和管理资源的使用,是可以便捷有效促进企业降本增效的方案。同时,在容器化转型浪潮中,企业也可以结合企业的云平台或者专业开源平台,通过容器与API调用结合的方案,建设GPU资源池并实现资源的虚拟化共享使用,相比硬件厂家提供的软硬虚拟化方案,也能提供更好的集中管理,并起到资源的灵活、高效利用的效果。
