


今年355万片等效H100,流向五大AI龙头
2024年五大AI巨头,拥有多少片英伟达GPU?
人工智能基础设施的数据难以精确获取。诸多报道中会出现诸如“某公司本季度在基础设施上花费了Xbn”“某公司购买了10万台H100”或者“拥有10万台H100集群”这类信息,但当笔者试图估算某家公司能够使用的计算资源时,却无法找到统一的数据。
在此,笔者试图从各类来源搜集信息,来大致估算以下两点:其一,截至2024年,预计各方会拥有多少计算能力?其二,预计2025年会有哪些变化?之后,笔者将简要阐述这对主要前沿实验室的培训计算可用性的意义。在讨论该问题之前,笔者想先说明几点注意事项。
这些数字是笔者在有限时间内依据公开数据估算得出的,可能存在误差,也可能遗漏了一些重要信息。
付费供应商很可能有更精准的估算,他们能够花费更多时间去详细分析诸如晶圆厂的数量、各晶圆厂的生产内容、数据中心的位置、每个数据中心的芯片数量等诸多细节,并得出精确得多的数字。若读者需要非常精确的估算,笔者建议向几家供应商中的一家购买相关数据。
英伟达芯片生产
首先要从最重要的数据中心GPU生产商Nvidia开始。截至11月21日,在Nvidia公布2025年第三季度财报之后,预计Nvidia该财年数据中心收入约为1100亿美元。这比2023年的420亿美元有所增长,预计2025年将达到1730亿美元(基于2026财年1770亿美元的估计)。
数据中心的收入绝大部分来自芯片销售。2025年的芯片销售额预计为650-700万GPU,几乎全部是Hopper和Blackwell型号。根据CoWoS-S和CoWoS-L制造工艺的预期比例以及Blackwell的预期量产速度,笔者估计Hopper和Blackwell型号分别为200万和500万。
2024年产量
有关2024年生产数字的资料来源很少,而且经常相互矛盾,但2024年第四季度的Hopper GPU产量估计为150万个(尽管其中包括一些H20芯片,因此这只是一个上限),而且各季度的数据中心收入比率表明,产量上限为500万个(这将假定每个H100同等产品的收入约为2万美元)。
这与今年早些时候估计的150万到200万台H100的产量相冲突--这种差异是否可以合理地归因于H100与H200、扩容或其他因素尚不清楚,但由于这与他们的收入数字不一致,笔者选择使用较高的数字。
此前的产量
为了评估目前以及未来谁拥有最多的计算资源,2023年之前的数据对整体格局的影响有限。这主要是因为GPU性能本身的提升,以及从英伟达的销售数据来看,产量已经实现了大幅增长。根据估算,微软和Meta在2023年各自获得了约15万块H100 GPU。结合英伟达的数据中心收入,2023年H100及同等级产品的总产量很可能在100万块左右。
GPU/TPU按组织计数
笔者试图估算微软、Meta、谷歌、亚马逊和XAI到2024年底将获得多少以H100当量表示的芯片,以及2025年的相关数量。
许多消息源称“英伟达46%的收入来自4个客户”,不过这可能存在误导性。查阅英伟达的10-Q和10-K可以发现,他们区分了直接客户和间接客户,46%这个数字指的是直接客户。然而,直接客户大多是中间商,比如SMC、HPE和戴尔,他们购买GPU并组装服务器供间接客户使用,这些间接客户包括公共云提供商、消费互联网公司、企业、公共部门和初创公司,而笔者所关注的公司属于“间接客户”这一范畴。
关于间接客户的信息披露相对宽松,可能也不太可靠。在2024财年(约2023年,文中所讨论的情况),英伟达的年报披露,“一个主要通过系统集成商和分销商购买我们产品的间接客户估计占总收入的约19%”。按照规定,他们需要披露收入份额超过10%的客户信息。所以,要么他们的第二个客户最多只有第一个客户规模的一半,要么存在测量误差。这个最大的客户可能是微软,有零星信息披露称,每季度有第二个客户的数量曾短暂超过10%,但这种情况不具有连贯性,而且不包括2023年全年或2024年前3个季度的情况。
估计2024年底H100等效芯片数量
微软,Meta
笔者考虑到微软身为最大的公有云之一,是OpenAI的主要计算提供商,自身没有像谷歌、可能还有亚马逊那样大规模的定制芯片安装基础,并且与英伟达似乎存在相对于同行的特殊关系(例如,他们显然率先获得了Blackwell芯片),所以推测这两个最大的客户极有可能都是微软。英伟达在2024年的收入份额不像2023年那般精确,其在第二季度和第三季度提及H1收入的13%,而第三季度仅“超过10%”,不过13%可作为一个合理的估计,这表明微软在英伟达销售中的份额相较2023年有所降低。
另有一些对客户规模的估计,数据显示,微软占英伟达收入的15%,其次是Meta Platforms占13%,亚马逊占6%,谷歌占约6%,但从消息来源难以确定这些数据对应的年份。截至2023年底,有关这些云提供商拥有H100芯片数量的报告(Meta和微软为15万片,亚马逊、谷歌和甲骨文各为5万片)与上文的数据更为契合。
这里有一个关键的数据点,即Meta宣称到2024年底Meta将拥有60万H100当量的计算能力。据说其中包含35万H100,其余大部分似乎将是H200和上个季度到货的少量Blackwell芯片。
倘若我们将这60万视为准确数据,并依据收入数字的比例,便能更好地估算微软的可用计算量比这高出25%至50%,即75万至90万H100等效值。
谷歌,亚马逊
笔者注意到,亚马逊和谷歌向来被视作在对英伟达收入的贡献方面处于较为靠后的位置。不过,二者的情况实则全然不同。
谷歌早已拥有大量自定义的TPU,而这TPU正是其内部工作负载所倚重的主要芯片。至于亚马逊,其内部AI工作负载看上去很可能要比谷歌小得多,并且亚马逊所拥有的数量相当的英伟达芯片,主要是为了通过云平台来满足外部GPU的需求,其中最为显著的当属来自Anthropic的需求。
下面先来看谷歌的情况。如前文所述,TPU是其用于内部工作负载的主要芯片。提供该领域数据的领先订阅服务Semianalysis在2023年底曾宣称:“谷歌是唯一一家拥有强大内部芯片的公司”,“谷歌具备近乎无与伦比的能力,能够以低成本和高性能可靠地大规模部署AI”,且称其为“世界上计算资源最丰富的公司”。自这些说法问世以来,谷歌在基础设施方面的支出一直维持在较高水平。
笔者对TPU和GPU的支出进行了2比1的估计(此估计或许较为保守),即假设每一美元的TPU性能等同于微软的GPU支出,由此得出的数据范围是在2024年年底拥有10万-150万H100当量。
亚马逊虽有自己的定制芯片Trainium和Inferentia,但它们起步的时间相较于谷歌的TPU要晚得多,并且在这些芯片的发展进程中似乎落后于前沿水平。亚马逊甚至推出1.1亿美元的免费积分以吸引人们试用,这一举措表明其芯片截至目前尚未呈现出良好的适应性。半分析指出:“我们的数据显示,Microsoft和Google在AI基础设施上的2024年支出计划将使他们部署的计算量远超过亚马逊”,并且“此外,亚马逊即将推出的内部芯片Athena和Trainium2仍然显著落后”。
然而,到2024年年中,情况或许已有所转变。在2024年第三季度财报电话会议上,亚马逊首席执行官安迪・贾西谈及Trainium2时表示“我们察觉到人们对这些芯片抱有浓厚兴趣,我们已多次与制造合作伙伴沟通,产量远超最初计划”。但由于当时他们“在接下来的几周内才开始增产”,所以在2024年其芯片似乎不太可能有大规模的供应。
XAI
笔者在此要介绍的最后一位重要参与者便是XAI。该机构发展极为迅速,在相关领域坐拥一些规模最大的集群,且有着宏大的发展计划。其在2024年底对外透露了一个正在运行的、拥有10万台H100的集群,不过就目前来看,似乎在为该站点提供充足电力方面存在一定的问题。
2025年Blackwell芯片预测
笔者注意到《2024年人工智能状态报告》对主要供应商的Blackwell购买量有所估计,其提到“大型云公司正在大量购买这些GB200系统:微软在70万-140万之间,谷歌在40万以及AWS在36万之间。有传言说OpenAI至少有40万GB200”。由于这些数字是芯片的总数,所以存在重复计算2024年Blackwell购买量的风险,故而笔者打了15%的折扣。
若依据微软的估计,谷歌和AWS购买英伟达的数量约为100万台,这与它们相对于微软的典型比例相符。这也会使微软占英伟达总收入的12%,此情况与其在英伟达收入中的份额于2024年的小幅下降态势相一致。
在这份报告里,Meta未被给出任何估计,但Meta预计明年人工智能相关基础设施支出将“显著加速”,这意味着其在英伟达支出中的份额将维持在高位。笔者假定到2025年,Meta的支出约为微软的80%。
对于XAI而言,其在这些芯片的相关内容中未被提及,不过埃隆・马斯克宣称他们将于2025年夏天拥有一个30万的Blackwell集群。考虑到马斯克有时会有夸张言论的情况,XAI似乎有可能在2025年底拥有20万至40万这样的芯片。
一架B200的H100值多少呢?为衡量产能增长,这是一个关键问题。训练和推理所引用的数字不同,就训练而言,当前(2024年11月)的最佳估计值是2.2倍。
对于谷歌,笔者假定英伟达芯片继续占其总边际计算的1/3。对于亚马逊,笔者假定为75%。这些数字存在较大不确定性,估计数对其较为敏感。
值得留意的是,仍然有诸多H100和GB200未被记录,且可能在其他地方有显著聚集,尤其是在英伟达10%的报告门槛之下。像甲骨文等云服务提供商以及其他较小的云服务提供商可能持有。
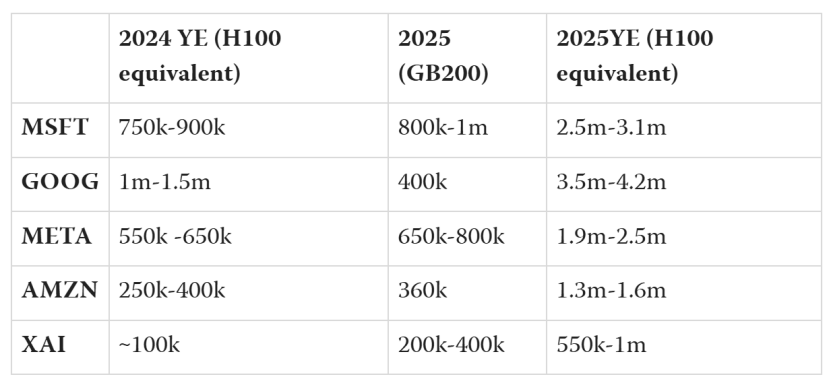
芯片数量估计摘要
模型训练注意事项
笔者在此所提及的上述数字,乃是对可用计算总量的估计情况。不过,想必许多人会更为关注用于训练最新前沿模型的那部分计算量。接下来,笔者将着重围绕OpenAI、Google、Anthropic、Meta以及XAI展开介绍。但需说明的是,这一切内容都颇具推测性,毕竟这些公司要么是私营性质,要么规模极为庞大,以至于无需对外披露这方面的成本明细。就拿谷歌来说,相关内容仅仅只是其业务的一小部分罢了。
据预计,OpenAI在2024年的培训成本将会达到30亿美元,其推理成本则为40亿美元。依照一位消息人士的说法,Anthropic“预计今年将会亏损约20亿美元,营收可达数亿美元”。这也就意味着,Anthropic的总计算成本要比OpenAI的70亿美元多出20亿美元。由于Anthropic的收入主要源自API,且应当具备正的毛利率,所以其推理成本将会大幅降低,由此可推断出,多出的20亿美元中的大部分是用于训练的,大概为15亿美元左右。即便与OpenAI相比,Anthropic在培训成本方面存在两个不利因素,但这似乎并未对其竞争力造成妨碍。这种情况看起来确实很有可能,因为Anthropic的主要云提供商是AWS,而我们已然了解到,AWS所拥有的资源通常要比为OpenAI提供计算资源的微软少。之前提到的《AI状态报告》中有传言称,微软将会向OpenAI提供40万个GB 200芯片,这一数量将会超过AWS传闻中的整个GB 200容量,所以极有可能使得OpenAI的训练能力远远高于Anthropic的训练能力。
笔者发现,谷歌的情况不太明晰。Gemini超1.0模型的训练计算量大约是GPT-4的2.5倍,不过在其发布9个月后,相比最新的Llama模型仅多出25%。正如我们所了解到的,谷歌或许比同行拥有更多的可用计算能力,然而,由于它既是一个主要的云提供商,又是一家大企业,所以其自身的需求也更多。谷歌的计算能力要强于Anthropic或OpenAI,甚至比Meta也要强,要知道Meta也有大量独立于前沿模型培训的内部工作流程,比如社交媒体产品的推荐算法。Llama 3在计算方面比Gemini要小,尽管它是在Gemini发布8个月后才推出的,这表明截至目前,Meta分配给这些模型的资源相较于OpenAI或Google而言略少一些。
再看XAI方面,据称其使用了2万个H100来训练Grok 2型,并且预计Grok 3型的训练将会使用多达10万个H100。鉴于GPT-4据称是在25000个英伟达A100 GPU上训练了90-100天,而H100的性能大约是A100的2.25倍,如此一来,Grok 2型的计算量将达到GPT-4的两倍,并且预计Grok 3型的计算量还会再增加5倍,从而使其接近行业领先水平。
需要注意的是,XAI并非所有的计算资源都来自于他们自己的芯片,据估计,他们从甲骨文云租用了16000个H100。倘若XAI能够像OpenAI或Anthropic那样将其计算资源合理地部分用于培训,笔者猜测它的培训规模或许会与Anthropic类似,略低于OpenAI和谷歌。
