


因配置不当,约5000个AI模型与数据集在公网暴露
除了可访问机器学习模型外,暴露的数据还可能包括训练数据集、超参数,甚至是用于构建模型的原始数据。
安全内参10月10日消息,一名安全研究人员透露,数千个机器学习工具已暴露在开放的互联网中,其中一些还属于大型科技公司。任何人都能访问这些工具,并存在敏感数据泄露的潜在风险。
这则消息表明,尽管公司和研究人员在人工智能研究上突飞猛进,但保护这些工具,仍需要依赖适用于其他类型账号的通用账号安全和身份验证最佳实践。
Reddit的安全研究人员兼首席安全工程师Charan Akiri在其研究报告中指出:“除了机器学习(ML)模型本身,暴露的数据还可能包括训练数据集、超参数,甚至有时是用于构建模型的原始数据。”
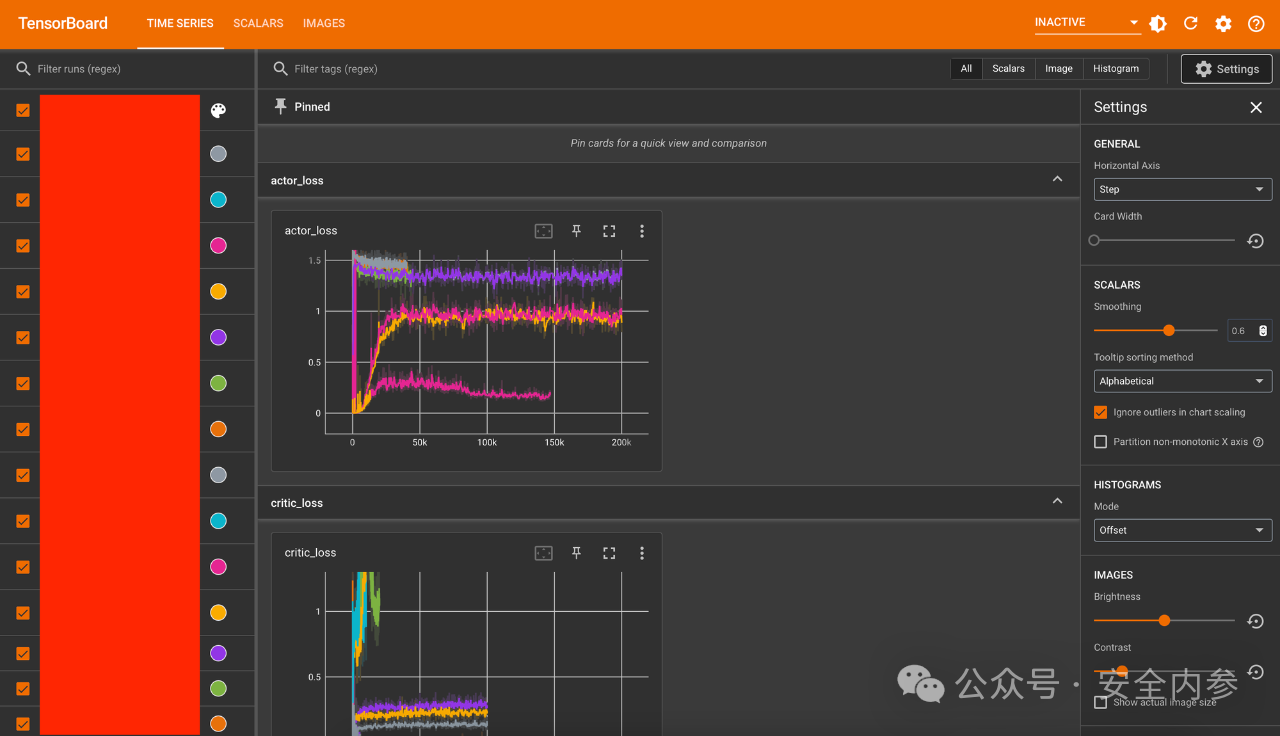
暴露的工具包括MLflow、Kubeflow和TensorBoard实例。这些工具通常用于帮助企业在云端训练和部署生成式AI模型,或可视化其结果。
Akiri在研究报告中写道:“这种配置错误使得未经授权的人员能够访问、下载,甚至运行敏感的机器学习模型和数据集。这类暴露事件本不应发生,因为这些平台应该仅限于内部使用。”
Akiri指出,他们已经能够识别出部分暴露实例的所有者,但他强调,“这只是整体暴露的一小部分,实际上可能还有许多公司尚未被我们识别出来。”
其中一家公司是日本的半导体制造商瑞萨电子(Renesas Electronics)。Akiri表示,通过控制面板证书中的线索,他们确认了一个机器学习工具属于瑞萨电子。外媒404 Media联系瑞萨电子请求对此事发表评论后,瑞萨电子立即撤下了暴露的控制面板,Akiri也通知了该公司这一问题。然而,瑞萨电子最终未对评论请求作出回应。
404 Media在访问几个可以通过开放互联网找到的MLFlow实例时,发现控制面板提供了创建“新运行”的选项。用户还能查看之前的实验记录,通常还能够执行与原用户相同或类似的任务。Akiri表示,他们发现了大约5000个暴露的MLFlow实例。
参考资料:404media.co
